Differenzierung innerhalb von Machine Learning
Dass Machine Learning ein Teilgebiet der Künstlichen Intelligenz darstellt, haben wir schon des Öfteren erklärt – und gleich der KI gibt es auch hier verschiedene Einteilungen; denn Lernen ist nicht gleich Lernen.
Mit maschinellen Lernverfahren kann erklärt werden, wie Computersysteme eine Fähigkeit erhalten bzw. erlernen, die Menschen und Tieren auf natürliche Weise gegeben ist. dank Machine Learning lernen die Systeme aus Ihren zur Verfügung gestellten Daten, den daraus geworbenen Informationen und erweitern mit neuen Erfahrungen beständig Ihren Wissensstand.
Flexibel und konsequent zu mehr Wissen
Die Algorithmen, die maschinellen Lernens bestimmen, können modellfrei direkt aus Daten „lernen“, und sind im Gegensatz zu den klassischen Programmen nicht an eine vorgegebene Gleichung als Modellrahmen für das zu erlernende Wissen gebunden. Somit ist nicht nur maximale Flexibilität garantiert, sondern auch eine konsequente und eine Verbesserung der Leistungsfähigkeit abhängig von der jeweiligen Anzahl der Datensätze.
Das Anwendungsfeld des Machine Learning ist so vielfältig wie facettenreich, dennoch sind die Methoden des maschinellen Lernens auf drei grundlegenden Lernarten zurückzuführen:
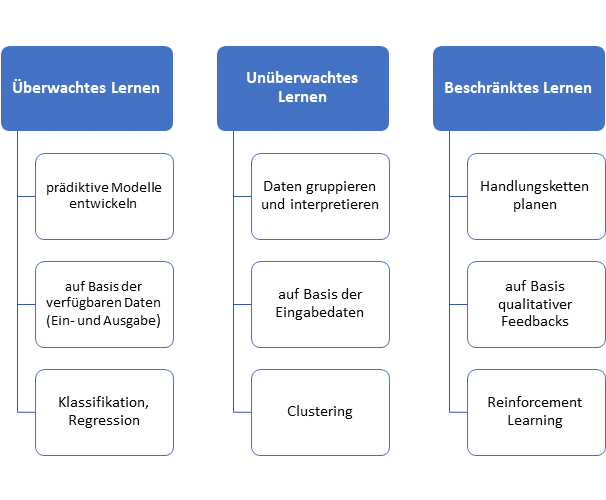
1. Überwachtes Lernen
In diesem Modell werden dem Lernenden bzw. dem Algorithmus neben der jeweiligen Aufgabe zur Kontrolle auch die richtige, also die gewünschte Lösung zur Verfügung gestellt. Somit wird gleichzeitig die Möglichkeit gegeben, potenzielle Fehlleistungen quantitativ zu beurteilen und das Modell dementsprechend anzupassen.
Überwachte Lernverfahren ermöglichen es, Daten zu kategorisieren oder generalisieren. Zu ihren typischen Vertretern zählen die Klassifikation und die Regression.
2. Unüberwachtes Lernen
Unüberwachte Lernverfahren hingegen arbeiten lediglich auf Basis der Eingabedaten, also ohne die Soll-Ausgabe. Sie ermöglichen es, in einer Menge von Daten Häufungen oder Ausreißer zu entdecken.
Das wohl berühmteste Anwendungsbeispiel des unüberwachten Lernverfahrens ist das Clustering.
3. Bestärkendes Lernen
Diese dritte Art des maschinellen Lernens soll an dieser Stelle nicht weiter betrachtet werden. unter bestärkendem Lernen versteht man, dass durch das Geben qualifizierter Feedbacks am Ende von Aktionsketten das Lernen komplexer Handlungsstrategien und Politiken ermöglicht wird.
Doch was ist der genaue Unterschied?
Überwachtes Lernen
Ziel überwachter Lernverfahren ist die Entwicklung eines Modells, das Vorhersagen trotz bestehender Unsicherheit trifft. Dazu wird eine gegebene Menge von Eingangsdaten und die dazugehörigen gewünschten Reaktionen genutzt, um ein Modell zu trainieren. Das trainierte Modell erlaubt es dann, sinnvolle Vorhersagen für das Ausgabeverhalten bei neuen Eingaben zu generieren.
Überwachtes Lernen tritt vor allem in Zusammenhang mit Klassifikationsmodellen auf; diese klassifizieren Eingangsdaten in Kategorien und sagen diskrete Ausgaben voraus, etwa ob eine E-Mail Spam ist oder nicht oder ob ein eingescannter Buchstabe ein »A« ist.
Die zweite große Gruppe von Verfahren aus dem Bereich des überwachten Lernens sind neben Klassifikationsverfahren die Regressionsverfahren. Diese sagen kontinuierliche Ausgaben voraus, beispielsweise Temperaturänderungen oder Kursentwicklungen. Eines der bekanntesten Verfahren ist die lineare Regression, die die Parameter eines vorgegebenen Modells so anpasst, dass die Gerade mit minimalem Gesamtfehler durch die Punktwolke vorgegebener Testpunkte verläuft. Ist das Modell gelernt, kann für unbekannte neue Eingangswerte der vermutliche Ausgangswert prognostiziert werden.
Unüberwachtes Lernen
Unüberwachte Lernverfahren finden versteckte Muster und Strukturen in Daten. Sie werden genutzt, um Schlussfolgerungen aus Datensätzen zu ziehen, die nur aus Eingangsdaten ohne zugehörige Ausgangsdaten bestehen.
Eines der am häufigsten genutzten unüberwachten Lernverfahren ist das Clustering. Hiermit wird ermöglicht, dass durch eine explorative Datenanalyse versteckte Muster oder Häufungen in den Daten aufgedeckt werden. Häufig wird hierfür der k-Means-Algorithmus verwendet. Mittels eines iterativen Verfahrens werden die Testpunkte nach und nach der vorgegebenen Anzahl von k-Zentren zugeordnet, in der Weise, dass die Summe der quadrierten Abweichungen von den Cluster-Zentren minimal ist.
Was hat man davon?
Das Ziel maschineller Lernverfahren ist also, aus Daten den maximalen Anteil an Informationen zu gewinnen und diese weiter zu Wissen zu verarbeiten. Auf diese Weise werden riesige Mengen an Rohdaten zu kompaktem, wettbewerbsvorteilhaftem Wissen bereitgestellt.
Auf diese Weise erhalten Unternehmen durch den Einsatz von Maschinellem Lernen Einblick in bisher unbekannte Zusammenhänge und Muster in ihren Daten.
Im Kern geht es beim maschinellen Lernen also um Wissensgewinnung und die verschiedenen Aufgaben, die daraus erwachsen. Werden beispielsweise die Zustände eines Prozesses über einen längeren Zeitraum erfasst, können die gewonnenen Muster genutzt werden, um den Prozess zu optimieren und Wettbewerbsvorteile zu erzielen. Da die Methoden des maschinellen Lernens per se generisch sind, ist ihre Anwendung in einem sehr weiten Kontext möglich – vorausgesetzt eine entsprechende Datenbasis liegt bereits vor oder kann erfasst werden.